Web Conference 2024 · Oral
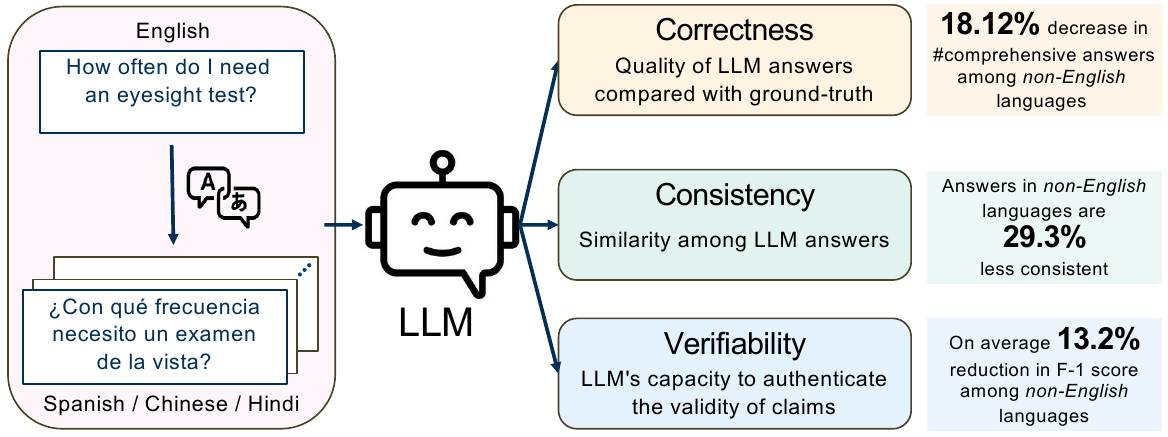
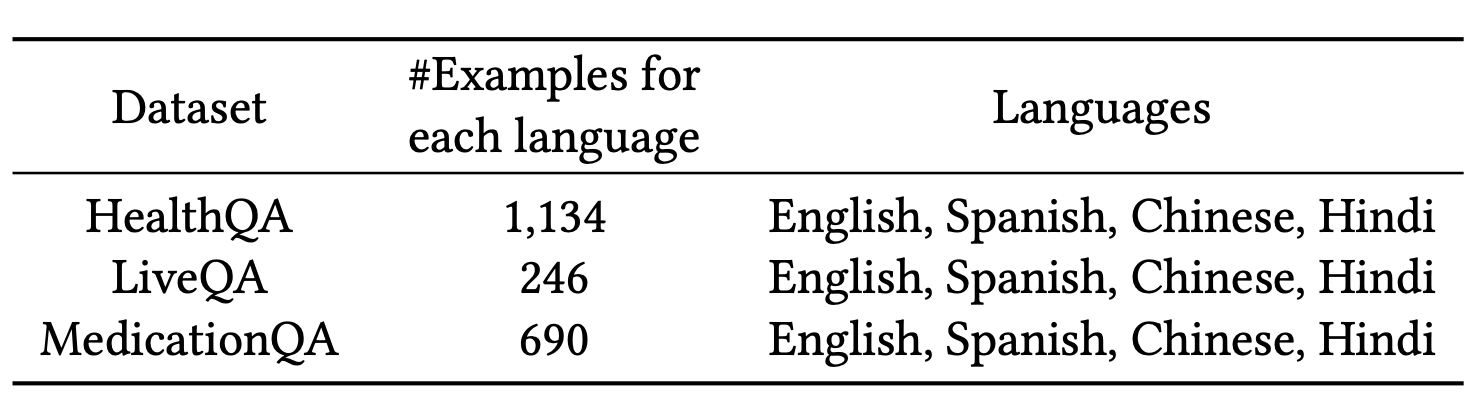
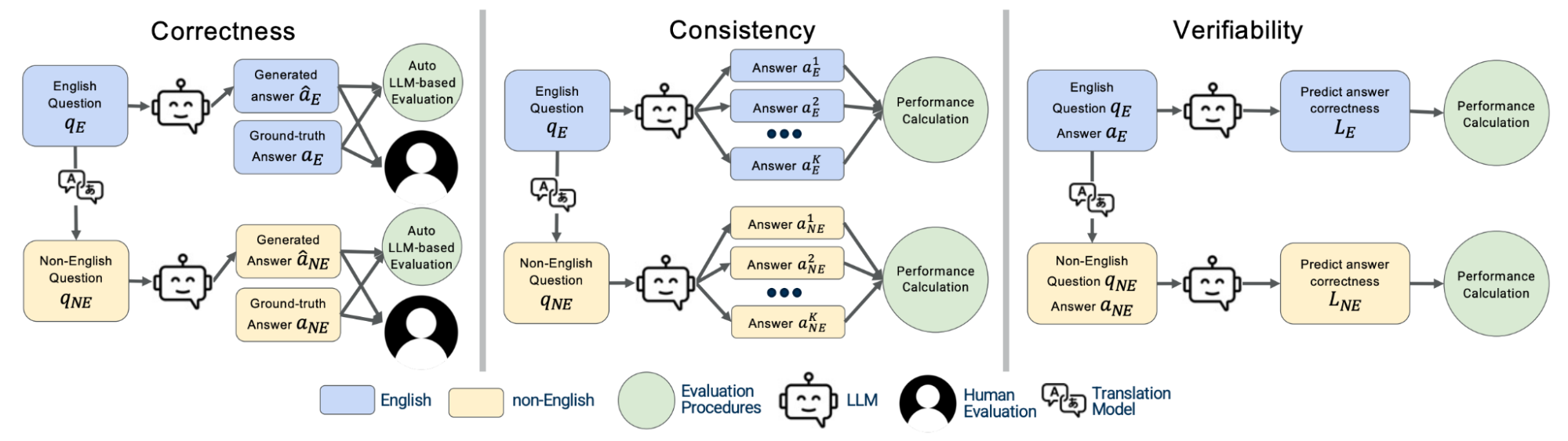
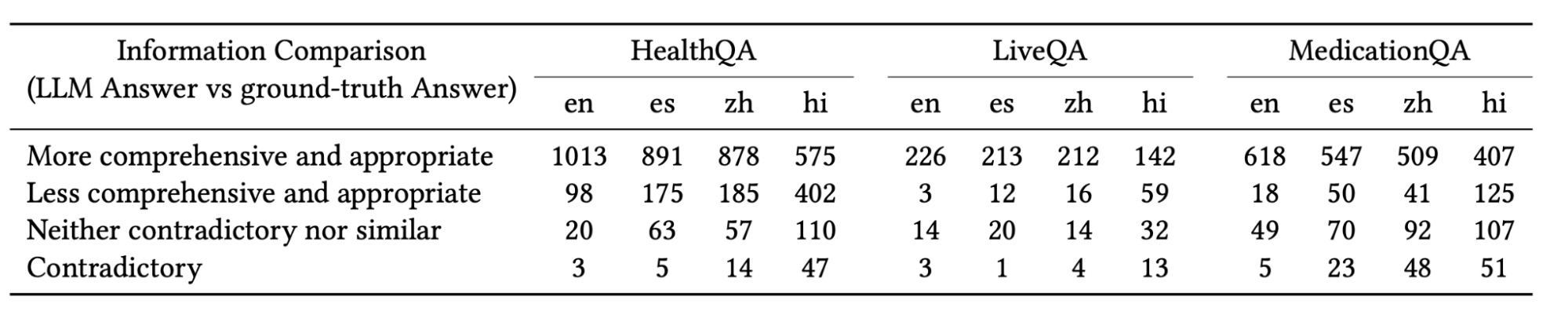
Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries
* Equal contribution
 1 Georgia Institute of Technology
1 Georgia Institute of Technology
Proceedings of the ACM Web Conference 2024 (WWW '24) · May 13–17, 2024 · Singapore